Apache Cassandra: A Practical Guide for Developers
Apache Cassandra is a distributed, leaderless database built for scalability and fault tolerance. Learn its core concepts, schema design rules, data types, and example queries in this practical guide.
Written by Sakib Sami: backend and distributed systems engineer focused on reliability, event-driven architecture, and production systems.
Apache Cassandra is one of the most powerful distributed databases used by companies like Netflix, Uber, and Apple to handle massive amounts of data with near-zero downtime. It’s designed for high availability, fault tolerance, and scalability, making it a favorite for mission-critical applications.
In this post, I’ll walk you through Cassandra’s core principles, schema design strategies, data modeling rules, and example queries that will help you use Cassandra effectively in real-world projects.
Why Cassandra?
Unlike traditional relational databases, Cassandra is leaderless and follows a peer-to-peer networking model. Every node in the cluster is equal, so if one node goes down, others can take over without disruption. This makes Cassandra inherently fault tolerant.
Another key difference: Cassandra is query-driven. Instead of modeling data first and worrying about queries later, you start with the application use cases and then design the schema based on query patterns.
Core Principles
- Leaderless Architecture: Any node can handle reads and writes. No single point of failure.
- Query-Driven Schema: Design tables for specific queries. Data duplication is acceptable.
- Primary Key Rules: Queries must include all columns from the primary key. Updates act as upserts.
- Replication: Use at least two replicas per data center to ensure durability and failover.
- Keyspace: A namespace that defines replication strategies across tables.
Schema Design Guidelines
-
One Query per Table – Build tables around queries, not entities.
-
No Joins, No Foreign Keys – Denormalize your data. Duplicates are fine.
-
Partition Key – Determines data distribution across nodes. Choose one that avoids hotspots.
-
Clustering Key – Defines the sort order of data within a partition.
-
Primary Key = Partition Key + Clustering Key.
-
Restrictions –
- No
ORDER BYon partition keys. - All partition key columns must be included in the
WHEREclause. - Primary keys cannot be updated (delete + insert instead).
- No
Partitions, Clustering, and Replication
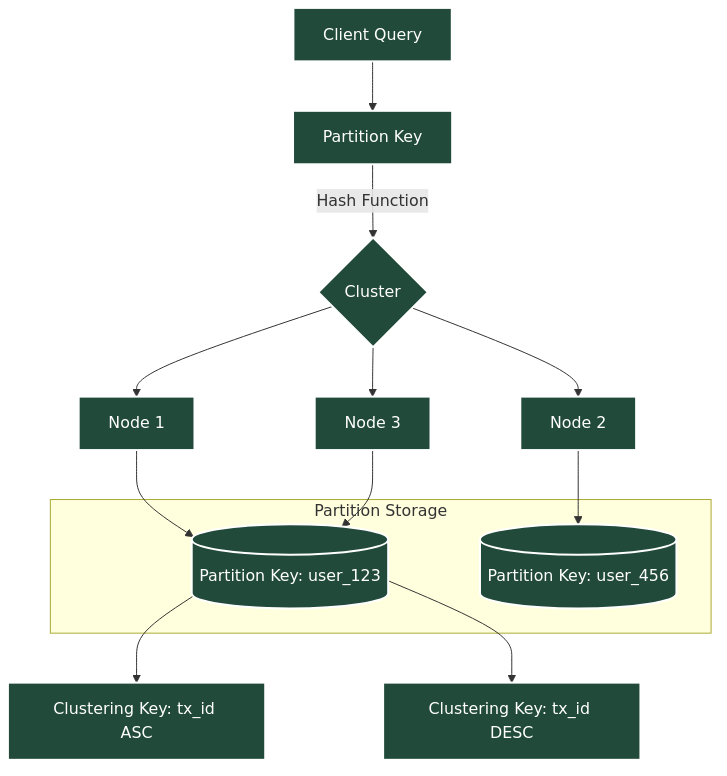
To understand Cassandra data distribution, think of three key components:
- Partition Key – Decides which node stores the data.
- Clustering Key – Orders rows inside the partition.
- Replication – Makes copies of data across multiple nodes/data centers for fault tolerance.
Data Types
Cassandra supports rich data types:
- Scalars:
text,int,bigint,uuid,timestamp,boolean,float,double, etc. - Collections:
list– Ordered, allows duplicates.set– Unordered, unique elements.map– Key-value pairs.
- Special:
timeuuid,inet,blob,counter.
Built-in Functions
now()– Generate a current timestamp UUID.dateOf(timeuuid)– Extract date from UUID.toTimestamp()– Convert to timestamp.writetime(column)– Get last write timestamp.ttl(column)– Time-to-live for column data.
Cassandra Write & Read Path
Understanding how Cassandra handles writes and reads will help you reason about performance, consistency levels, and operational tuning.
Write Path: Commit Log → Memtable → SSTables

What happens:
- Each replica appends to the commit log (durability), updates the memtable (fast in-memory write), and flushes to SSTables later.
- Compaction periodically merges SSTables, removes duplicates and expired tombstones, and improves read performance.
- The coordinator returns success when the chosen consistency level is satisfied (e.g., QUORUM).
Read Path: Bloom Filters → Index Summary → Page Cache → SSTables
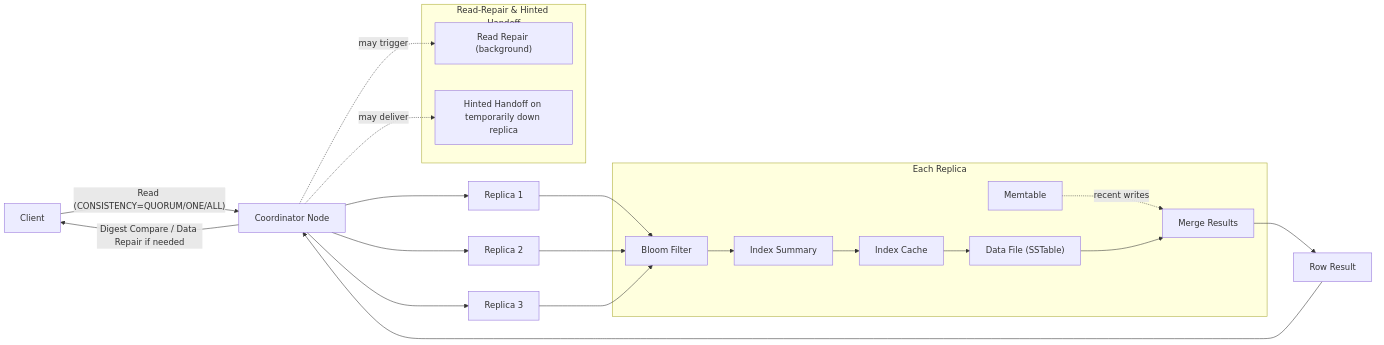
What happens:
- Reads check Bloom filters (to skip SSTables that don’t contain the key), then consult index summary/cache and finally fetch the row from the SSTable (and memtable for latest writes).
- The coordinator reconciles results using timestamps, satisfying the chosen consistency level.
- Read Repair can update stale replicas; Hinted Handoff helps catch up replicas that were temporarily down.
Example Queries
Create Table
CREATE TABLE ads.txs
(
user_id UUID,
tx_id UUID,
tx_time TIMESTAMP,
PRIMARY KEY (user_id, tx_id)
) WITH CLUSTERING ORDER BY (tx_id ASC);Insert Data
INSERT INTO ads.txs (user_id, tx_id, tx_time)
VALUES (c0ff412b - cda0 - 40d8 - 8059 - f19eb4a77cc1,
9c1c7894 - 19dc - 4a22 - ade2 - 13271929c263,
toTimestamp(now())) IF NOT EXISTS;Update Data
UPDATE ads.txs
SET tx_time = toTimestamp(now())
WHERE user_id = uuid()
AND tx_id = uuid() IF EXISTS;Select Data
SELECT *
FROM ads.txs
WHERE user_id = ?
AND tx_id = ?;Delete Data
DELETE
FROM ads.txs
WHERE user_id = ?
AND tx_id = ?;Practice Use Cases
- Ad Click Tracking:
(user_id, ad_id) - Transactions:
(user_id, transaction_id, tx_time)
Each query gets its own table, even if that means duplicating data.
Rebalancing in Cassandra
Rebalancing ensures even data distribution when nodes are added or removed.
- Add Node: Data is automatically streamed from existing nodes to the new one.
- Remove Node: Data is redistributed to maintain replicas.
This process is automatic and continuous, keeping Cassandra clusters balanced and performant.
Common Mistakes to Avoid
Even experienced developers run into issues when first working with Cassandra. Here are some pitfalls to watch out for:
-
Modeling Data Like SQL: Cassandra is not relational. Avoid joins and normalization. Instead, duplicate data to match query needs.
-
Choosing a Poor Partition Key: Picking a low-cardinality partition key (e.g.,
gender,country) can cause hotspots and uneven data distribution. Always choose keys that spread data evenly. -
Forgetting Replication Strategy: Default replication might not fit your needs. Always configure
NetworkTopologyStrategyfor production workloads. -
Overusing Batch Writes: Batches in Cassandra are not for performance, they are for atomicity across partitions. Misusing them can hurt performance.
-
Expecting ORDER BY Like SQL: Cassandra only supports ordering within clustering keys. Trying to force full dataset ordering will lead to frustration.
-
Updating Primary Keys: Primary keys are immutable. If you need to change one, delete the row and insert a new one.
-
Ignoring Consistency Levels: Cassandra allows tuning consistency per query (e.g.,
ONE,QUORUM,ALL). Ignoring this can cause unexpected read/write results.
Final Thoughts
Apache Cassandra shines in scenarios where uptime, scalability, and fault tolerance are critical. But it requires a different mindset than relational databases: think queries first, accept denormalization, and design with partitions in mind.
If you’re building applications that need to scale globally, like messaging, IoT platforms, or recommendation engines, Cassandra is a strong choice.
Need help with systems like this?
For consulting, architecture reviews, and backend delivery work, I operate through SuberaHQ, focused on deliberate software engineering for teams building production systems.