Apache Kafka: A Practical Guide for Developers
Apache Kafka is a distributed streaming platform built for scalability, fault tolerance, and high throughput. Learn its core concepts, topics, partitions, consumer groups, serialization formats, and stream processing features in this hands-on guide.
Written by Sakib Sami: backend and distributed systems engineer focused on reliability, event-driven architecture, and production systems.
Apache Kafka has become the backbone of real-time data infrastructure for companies like LinkedIn, Netflix, and Uber.
It is designed to handle high-throughput, fault-tolerant, distributed event streaming with near real-time
guarantees.
In this guide, we’ll cover Kafka’s architecture, core concepts, schema management, consumer groups, and stream processing, all explained with practical insights to help developers build production-ready applications.
Why Kafka?
Unlike traditional message queues, Kafka is not just a broker, it’s a distributed event streaming platform.
Key advantages:
- High throughput: Millions of messages per second at scale.
- Durability: Data is persisted on disk and replicated across brokers.
- Scalability: Horizontal scaling with partitions and brokers.
- Flexibility: Use Kafka as a message bus, event log, or real-time analytics backbone.
Kafka Architecture
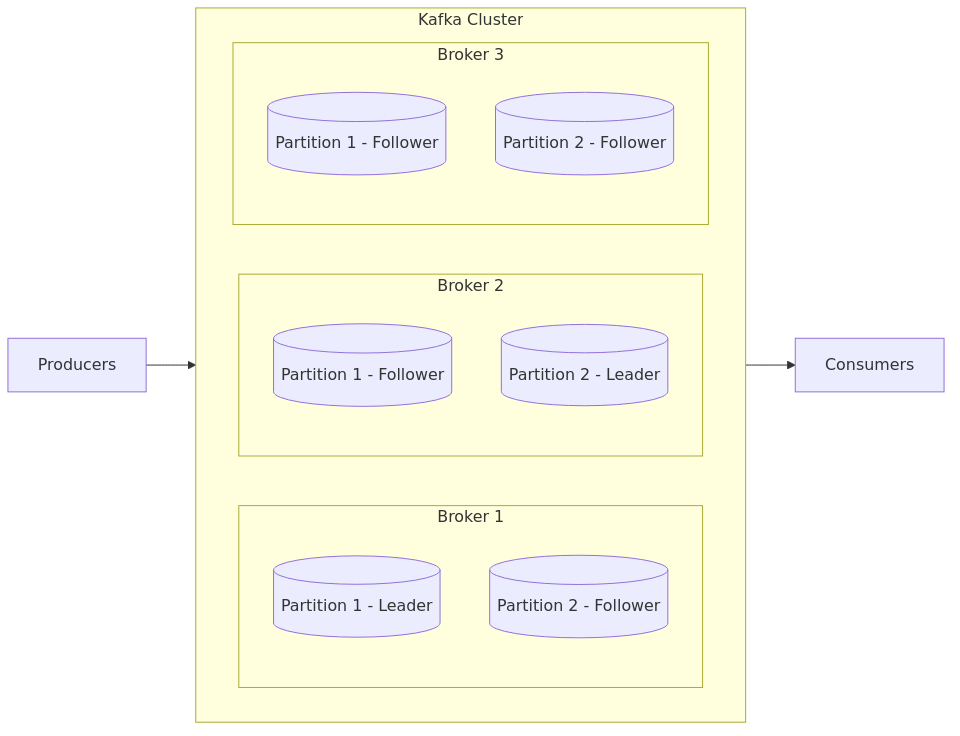
Core Principles
- Leader-Follower Architecture: Producers write to the partition leader; followers replicate the data for fault tolerance.
- Topic-Based Messaging: Topics are append-only logs storing ordered events.
- Partitions for Scalability: Topics are split across brokers for parallelism.
- Consumer Groups: Multiple consumers can share the workload by dividing partitions.
- Durability with Replication: Default replication factor is 3; ensures high availability.
- Delivery Semantics: Kafka supports at least once, at most once, and exactly once processing.
Topics
A topic in Kafka is similar to a table in a database:
- Stores a stream of immutable messages.
- Can be serialized in JSON, Avro, Protobuf, or custom formats.
- Messages have a time-to-live (default: 1 week).
- Replication ensures durability and failover.
Partitions & Offsets
Kafka achieves scalability and ordering with partitions:
- A topic can have many partitions, distributed across brokers.
- Within a partition, messages are ordered.
- Each message has an offset (a unique incremental ID).
- Offsets are never reused, even if data is deleted.
⚠️ Best practice: choose the number of partitions carefully, load test, and avoid exceeding broker limits (e.g., 4K partitions per broker).
Message Keys
A message key determines how messages are distributed:
- Key = NULL → Round-robin distribution across partitions.
- Key ≠ NULL → All messages with the same key go to the same partition (ordering guarantee).
- Kafka uses the Murmur2 hashing algorithm.
💡 Example: In a money transfer system, use customer_id as the key so all transactions for a customer remain ordered.
Message Format:
- Key (nullable)
- Value (usually required)
- Headers (metadata map)
- Partition + Offset
- Timestamp
- Compression (none, gzip, snappy, etc.)
Consumer Groups
Consumers in Kafka scale horizontally with consumer groups:
- Each partition is consumed by only one consumer in a group.
- Multiple groups can read the same topic independently.
- If a consumer crashes, Kafka reassigns its partitions.
Delivery Semantics:
- At least once → Default, may cause duplicates.
- At most once → Lowest latency, risk of data loss.
- Exactly once → Achieved with Kafka Streams/Transactional API.
Replication & Durability
- Typical replication factor: 3.
- Ensures high availability and failover.
- With higher replication:
- Disk usage grows.
- Write latency increases (especially with
acks=all).
Acknowledgements (acks):
acks=0→ Fire-and-forget (fastest, possible data loss).acks=1→ Leader acknowledgement only.acks=all→ Leader + all replicas (safest, slower).
Serialization & Schema Registry
Kafka supports multiple serialization formats:
- Avro (binary, schema-based) – most common.
- Protobuf, Thrift – alternatives with strong typing.
- Schema Registry ensures data consistency:
- Producers attach schema version with data.
- Consumers fetch schema and deserialize accordingly.
⚠️ Note: Avro doesn’t support date type directly.
ZooKeeper vs KRaft
- ZooKeeper → Used historically for cluster metadata and coordination.
- KRaft → Kafka’s new built-in consensus protocol.
- Kafka 3.x supports both.
- Kafka 4.0 and above will remove ZooKeeper entirely.
Kafka Streams
Kafka Streams is a stream processing library built into Kafka.
Supports:
- Transformations (
map,filter,groupBy,aggregate) - Joins across topics
- Windowed operations (e.g., hourly counts)
- Publishing results back to topics
Example use cases:
- Fraud detection
- Real-time analytics dashboards
- Event-driven microservices
Rebalancing in Consumer Groups
Rebalancing redistributes partitions when:
- A consumer joins or leaves a group.
- New partitions are added.
Steps:
- Trigger – Membership or partition changes.
- Coordinator – One broker manages partition assignments.
- Assignment – Partitions balanced across consumers.
- Cooperative Rebalance (≥ Kafka 2.3) – Minimizes downtime by allowing consumers to keep partitions during reassignment.
Common Mistakes to Avoid
- Too Many Partitions – Causes overhead; always benchmark.
- Misusing Batches – Batches ensure atomicity, not performance boosts.
- Ignoring Schema Evolution – Always manage schema compatibility in production.
- Low-Cardinality Keys – Leads to hotspots and uneven distribution.
- Expecting SQL-like Ordering – Ordering only within partitions, not across the topic.
Final Thoughts
Apache Kafka is more than a message broker, it’s a foundation for event-driven systems.
It powers real-time analytics, streaming ETL, and microservices communication at scale.
To use Kafka effectively:
- Choose partition keys wisely.
- Configure replication & acks for your SLA.
- Use schema registry for long-term compatibility.
- Design for consumer groups & rebalancing.
If your applications require real-time, scalable, fault-tolerant event pipelines, Kafka is the platform to bet on.
Need help with systems like this?
For consulting, architecture reviews, and backend delivery work, I operate through SuberaHQ, focused on deliberate software engineering for teams building production systems.