On October 20, 2025, a DNS issue in AWS US-EAST-1 caused a significant outage that rippled across the internet. Services relying on this region, including APIs, SaaS platforms, and consumer apps faced downtime, reminding us how a single regional failure in a hyperscale cloud can impact millions of users.
This incident highlights the importance of resilience planning, multi-AZ architectures, and multi-cloud deployments to reduce systemic risk.
Why It Matters
Cloud outages are rare but inevitable. Even with AWS’s world-class infrastructure, US-EAST-1 has historically been a single point of failure for many companies that rely on it exclusively.
Key lessons:
- Multi-AZ deployment isn’t enough: if all traffic is pinned to a single AWS region.
- DNS failures are cascading: if resolution breaks, apps can’t connect to healthy services.
- Vendor lock-in is a risk: if your stack is tightly coupled to one provider, you’re exposed to their failures.
High Availability (Multi-AZ)
Within AWS, Availability Zones (AZs) are designed to isolate failures. A well-architected service should:
- Deploy workloads across at least 3 AZs in a region.
- Use Elastic Load Balancing (ELB) or Application Load Balancer (ALB) to route across AZs.
- Enable RDS Multi-AZ replication or Aurora cluster replication.
- Ensure stateless compute (ECS/EKS/EC2) so workloads fail over seamlessly.
⚠️ However, during a regional service (DNS) outage, multi-AZ deployments are not sufficient, because the failure is systemic to the entire region.
Multi-Region Resilience
To survive regional outages:
- Active-Active Multi-Region: run workloads simultaneously in multiple AWS regions (e.g., US-EAST-1 + US-WEST-2).
- Active-Passive Failover: keep a secondary region warm, switch traffic using Route 53 health checks or global load balancers.
- Data Replication: use services like DynamoDB Global Tables, Aurora Global Database, or S3 Cross-Region Replication.
📌 Best practice: Treat multi-region as mandatory if downtime directly impacts revenue.
Multi-Cloud Strategy
For critical businesses, multi-cloud can be a safeguard against provider-wide risks:
- Cloud-agnostic orchestration: use Kubernetes or Terraform to deploy across AWS, GCP, and Azure.
- DNS abstraction: leverage providers like Cloudflare or Akamai instead of relying solely on AWS Route 53.
- Cross-cloud storage & compute: replicate data to GCP/Azure while running active workloads in AWS.
- Service selection: avoid deep lock-in with cloud-native PaaS (like DynamoDB or BigTable) if resilience is the priority.
⚠️ Trade-off: Multi-cloud increases operational complexity and cost. It’s best suited for businesses where downtime = millions lost.
Example Architectures
Multi-AZ (High Availability inside one AWS region)
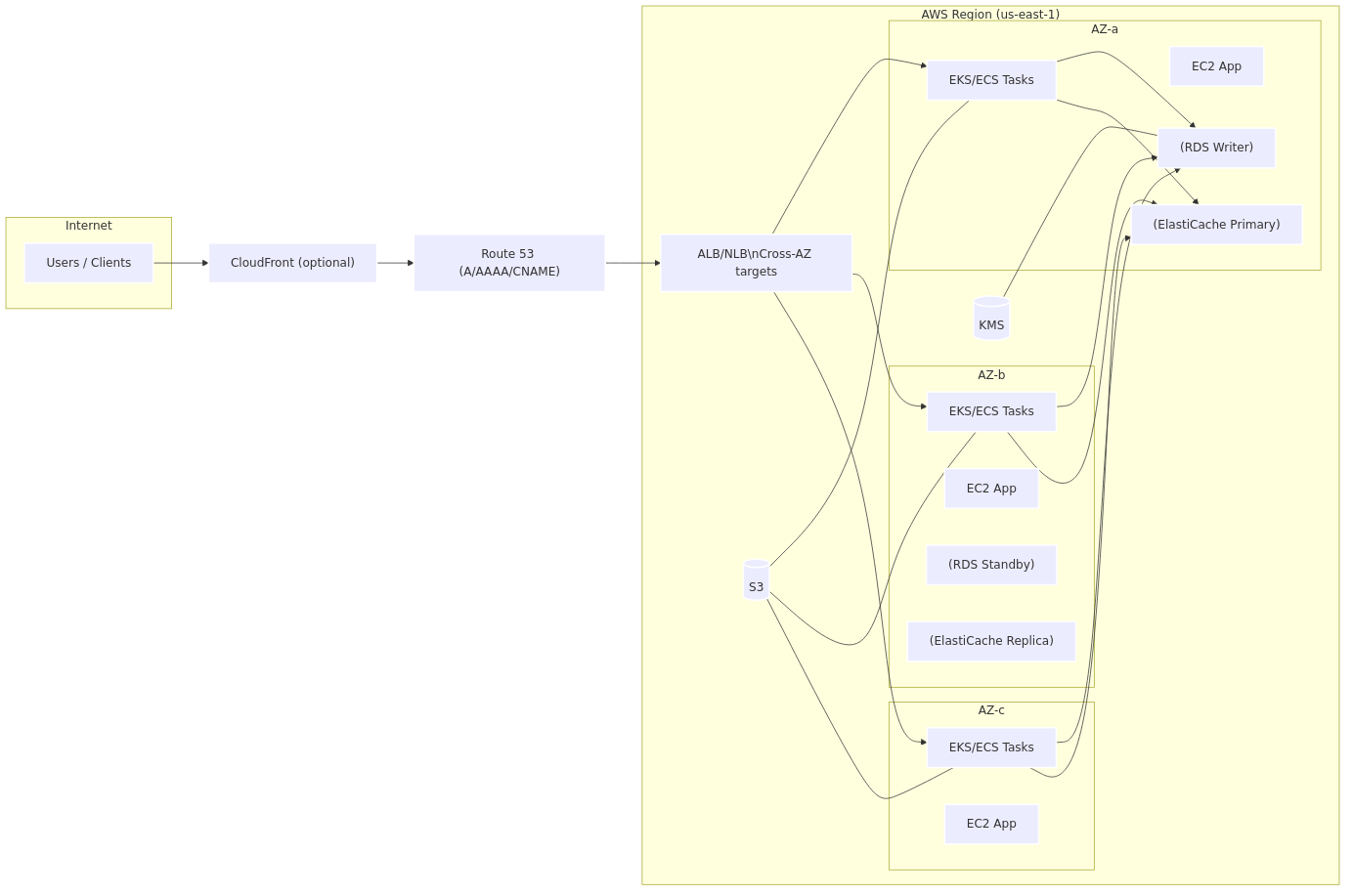
Takeaway: Great against AZ failures, but regional/control-plane issues (e.g., DNS) can still take you out.
Multi-Region Active-Active (survives a regional event)
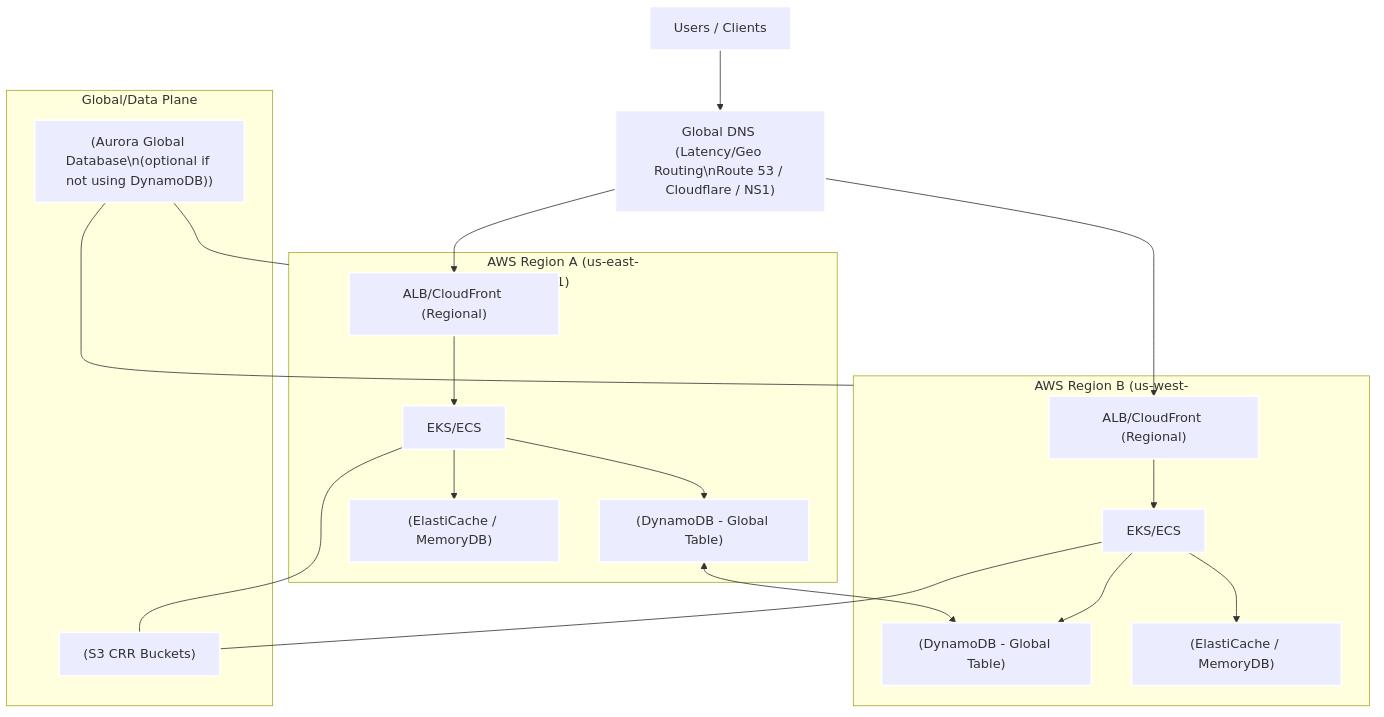
Notes
- Prefer DynamoDB Global Tables for true active-active writes with built-in conflict resolution.
- If using Aurora Global, treat one region as writer and others as readers (or carefully manage write forwarding).
Multi-Cloud (Provider resilience) with shared control plane patterns
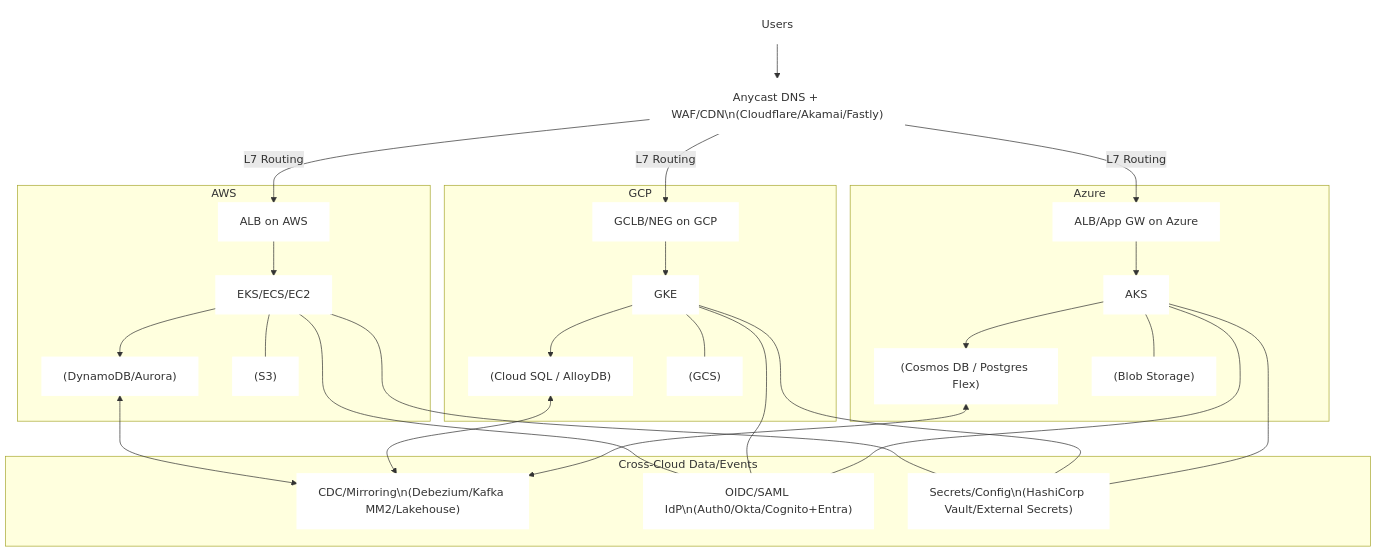
Design cues
- Control plane abstraction: Kubernetes + Terraform + Vault unify provisioning/secrets.
- Authentication: one IdP across clouds.
- Data: replicate via CDC (Debezium) or Kafka MirrorMaker 2; object storage via batch sync.
- Start read-mostly in secondary clouds, then graduate to active-active where conflict-free.
Common Mistakes to Avoid
- Single-Region Dependency: treating one AWS region as “always up.”
- DNS Blind Spot: ignoring DNS redundancy and caching strategies.
- Deep Vendor Lock-In: making it impossible to run workloads elsewhere.
- Underestimating Cost of Downtime: saving on infra but losing millions during outages.
Final Thoughts
The AWS US-EAST-1 outage was another reminder that resilience is not optional. Multi-AZ helps against localized failures, but only multi-region or multi-cloud truly protects against systemic ones.
To future-proof your architecture:
- Always deploy across multiple AZs.
- Consider multi-region if availability is business-critical.
- Adopt multi-cloud if downtime costs outweigh complexity.
Outages will happen. Resilience is a design choice.