Building a Data Pipeline with Debezium & Apache Pulsar
Turn database changes into real-time streams with CDC, sane schemas, and production-grade operations.
Written by Sakib Sami: backend and distributed systems engineer focused on reliability, event-driven architecture, and production systems.
Why
In the era of modern data-driven applications, the significance of data streaming is continuously on the rise. This upward trend can be attributed to various factors, including real-time data processing, scalability, event sourcing, data transformation, and complex event processing.
In this article, we will explore an example where data streaming is essential and demonstrate how to implement it using Debezium, Apache Pulsar, and Go.
Use Case
Imagine that we are developing an online bookstore similar to Amazon. Our tech stack includes PostgreSQL as the primary data storage, Golang for building the backend API, and Elasticsearch for efficient data searching. The initial challenge we encounter is how to efficiently synchronize data from PostgreSQL to Elasticsearch.
Requirements
Functional:
- Efficient data synchronization from PostgreSQL to Elasticsearch.
- Near-real-time data processing for changes.
Non-Functional:
- Scalability in data synchronization to handle increasing data volumes.
- Low-latency data synchronization for real-time responsiveness.
- Secure data transfer and storage during synchronization.
- Fault-tolerant data synchronization to handle potential failures.
- Monitoring and logging for tracking synchronization performance and troubleshooting.
- Minimal impact on the performance of the source PostgreSQL database.
- Compliance with data privacy and security regulations in data handling and storage.
Key Considerations
To accomplish this, we require a system capable of effectively capturing data from PostgreSQL while also being scalable. An established solution that fulfills these criteria is Debezium. Once Debezium captures the data, it promptly forwards it to a message queue to alleviate the workload and speed up processing. Now, we require a message queue that can effectively store the data, is scalable, operates with minimal latency, and ensures fault tolerance. In this solution we will be using Apache Pulsar which meets the above requirements.
High Level Overview
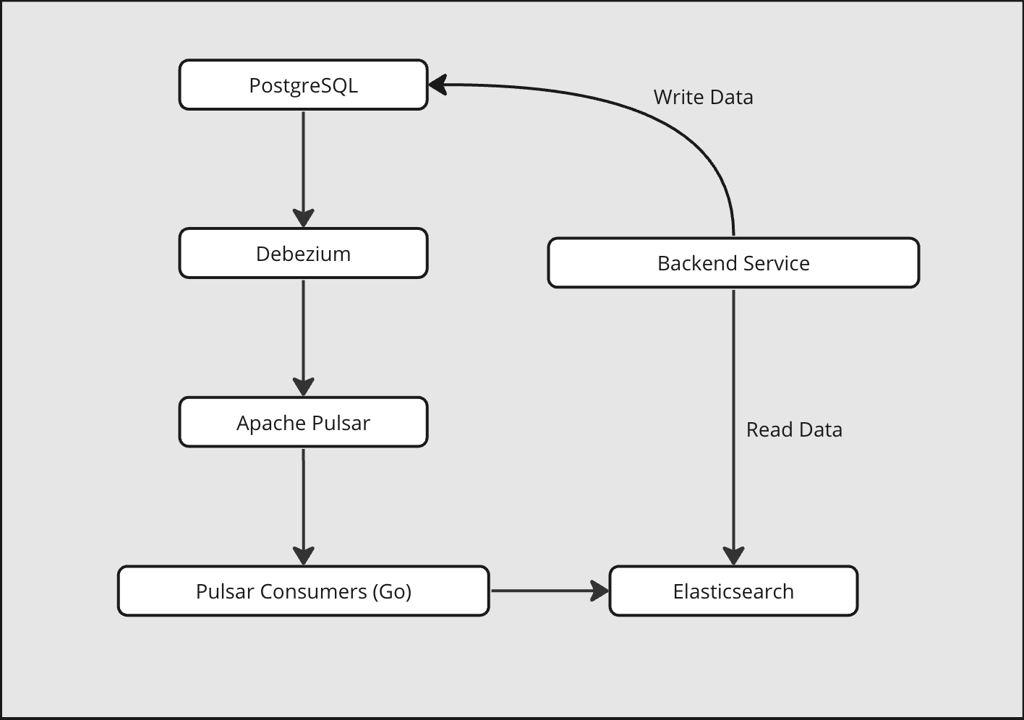
Implementation
- Data alterations in a table will be directed to a dedicated topic, ensuring data isolation for each table and facilitating easy scalability as data volume increases for a particular table.
- In Apache Pulsar, topic partitions can be dynamically expanded or reduced, guaranteeing automatic partition scaling in response to data growth.
- In terms of implementation, a consumer will consume data from a designated topic, ensuring the flexibility to scale consumers as required. To maintain the expected performance, it’s essential to scale consumers as data volume increases.
Setup
Debezium using docker-compose
// application.properties
debezium.sink.type=pulsar
debezium.sink.pulsar.client.serviceUrl={pulsar_server_url}
debezium.sink.pulsar.client.authParams=token:{jwt_auth_token}
debezium.sink.pulsar.client.authPluginClassName=org.apache.pulsar.client.impl.auth.AuthenticationToken
debezium.sink.pulsar.tenant={tenant_name}
debezium.source.connector.class=io.debezium.connector.postgresql.PostgresConnector
debezium.source.database.hostname={postgresql_host}
debezium.source.database.port={postgresql_port}
debezium.source.database.user={postgresql_username}
debezium.source.database.password={postgresql_password}
debezium.source.database.dbname={postgresql_database_name}
debezium.source.plugin.name=pgoutput
debezium.source.table.include.list={postgresql_tables_comma_seperated}
debezium.source.database.server.name={give_a_random_name}
debezium.format.key=json
debezium.format.value=json
debezium.source.topic.prefix={pulsar_topic_prefix}
debezium.source.publication.autocreate.mode=filtered// docker-compose.yml
version: '3.1'
services:
debezium_server:
image: docker pull debezium/server:2.3.3.Final
volumes:
- "./application.properties:/debezium/conf/application.properties"Please verify that the database has logical Write-Ahead Logging (WAL) enabled. When we execute the docker-compose command, it will retrieve data from the database and send it to Pulsar. At this stage, our data is now within Pulsar, and it’s time to transfer the data from Pulsar to Elasticsearch.
Install go pulsar client
go get -u github.com/apache/pulsar-client-go/pulsarInitialize go client,
client, err := pulsar.NewClient(pulsar.ClientOptions{
URL: { ServiceUrl },
OperationTimeout: 30 * time.Second,
ConnectionTimeout: 30 * time.Second,
Authentication: {pulsar_jwt_token}, // format = token:jwt_token
})
if err != nil {
panic(err)
}Subscribe to topic
consumer, err := pulsarCon.Subscribe(pulsar.ConsumerOptions{
Topics: []string{topic},
Type: pulsar.Shared,
SubscriptionName: {subscription_name},
SubscriptionInitialPosition: pulsar.SubscriptionPositionLatest,
})
if err != nil {
panic(err)
}
for cm := range consumer.Chan() {
msg := cm.Message
// transform data as needed and send to elastic
// after processing execute cm.Ack(msg) for acknowledgement
// and cm.Nack(msg) to re-process at a later time
}Note that pulsar.Shared allows multiple consumers to consume from same topic.
Now, we should have our data in Elasticsearch. To ensure the integrity of the Elasticsearch index, we can query it and validate some data to confirm that all the expected data is present.
To learn more about Apache Pulsar and Debezium go over their documentation.
Your caffeine-powered contribution keeps the code flowing and the ideas brewing! ☕💡

Need help with systems like this?
For consulting, architecture reviews, and backend delivery work, I operate through SuberaHQ, focused on deliberate software engineering for teams building production systems.