Weaviate: A Practical Guide for Developers
Weaviate is a vector database built for semantic search, recommendations, and RAG pipelines. Learn its core concepts, schema design, queries, replication, and real-world use cases in this hands-on guide.
Written by Sakib Sami: backend and distributed systems engineer focused on reliability, event-driven architecture, and production systems.
Weaviate has emerged as a leading vector database powering semantic search, recommendations, and retrieval-augmented generation (RAG) pipelines. It is designed for AI-native applications, combining embeddings, structured data, and hybrid search in a horizontally scalable, fault-tolerant system.
Why Weaviate?
Unlike traditional databases, Weaviate is built from the ground up for vectors and semantics.
Key advantages:
- Native vector search – powered by HNSW indexes.
- Hybrid search – combine keyword (BM25) + semantic vector search.
- Schema-first model – structured classes + embeddings.
- Multi-tenancy – isolated tenant data within the same cluster.
- Extensible with modules – built-in integrations for OpenAI, Cohere, Hugging Face, and more.
- Scalability – replication + sharding with automatic rebalancing.
Weaviate Architecture
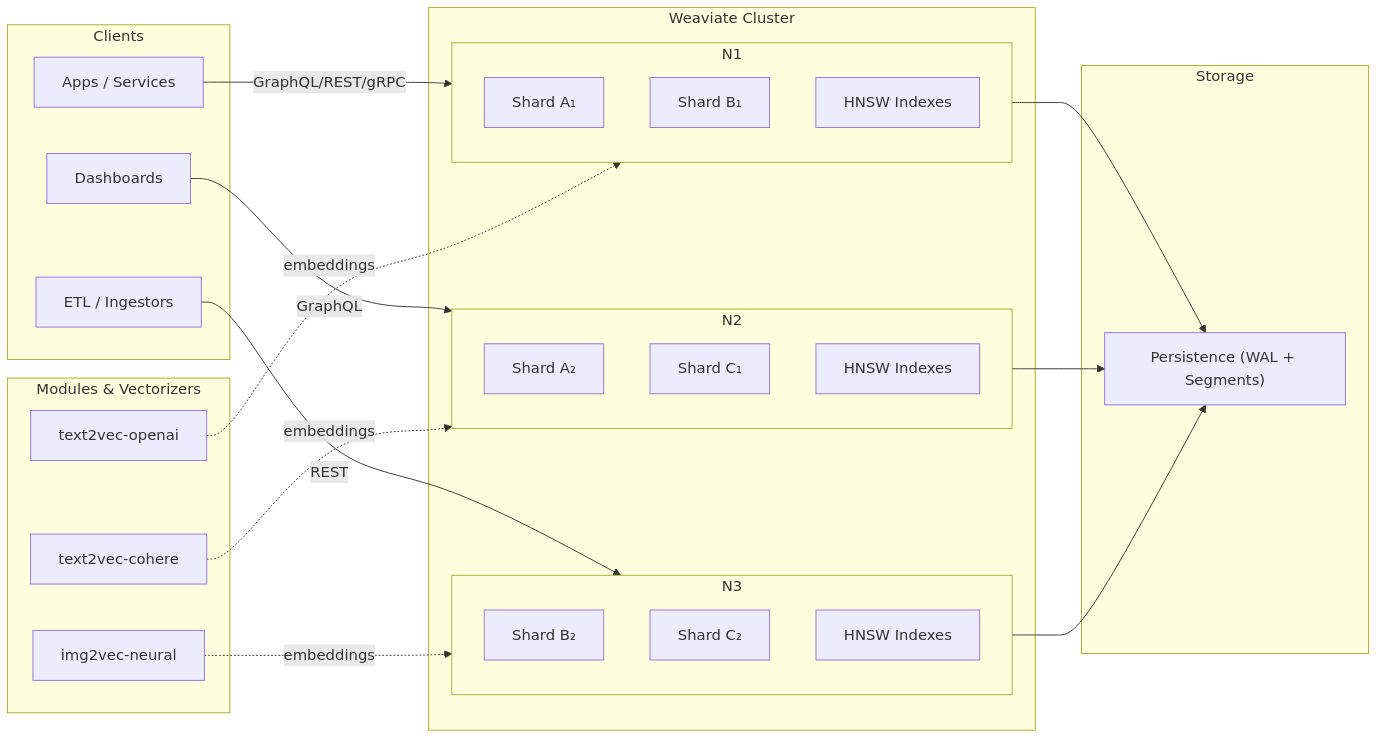
Core Principles
- Objects & Classes – data is stored as objects grouped by classes (similar to rows in a table).
- Properties & Vectors – each object has structured fields + a dense embedding vector.
- GraphQL API – primary query interface (also REST & gRPC).
- Vectorizers – generate embeddings via built-in modules or external pipelines.
- Cross-references – connect entities like foreign keys in relational systems.
Schema Design
- Class – defines structure (like
Article,Product,Review). - Properties – fields inside a class (
text,string,int,boolean,date,geoCoordinates). - Vectorizer – module used (e.g.,
text2vec-openai). - Indexes – HNSW parameters (
efConstruction,maxConnections) tune performance.
⚠️ Best practice: Always define schema up front for clarity and consistency.
Queries
Weaviate supports vector, hybrid, and filtered queries.
Vector Search:
{
Get {
Article(
nearText: { concepts: ["climate change"] }
limit: 3
) {
title
url
}
}
}Hybrid Search:
{
Get {
Product(
hybrid: { query: "red running shoes", alpha: 0.7 }
limit: 5
) {
name
price
}
}
}Filtered Vector Search:
{
Get {
Review(
nearVector: { vector: [0.12, 0.45, 0.89, ...] }
where: {
path: ["rating"]
operator: GreaterThan
valueInt: 4
}
) {
text
rating
}
}
}RAG Example

Replication & Sharding
- Replication – multiple copies of data across nodes for durability.
- Sharding – splits class objects across nodes for scalability.
- Automatic Rebalancing – redistributes data when nodes are added/removed.
Data Types
string– exact match field.text– full-text, tokenized for BM25.int/number– numeric fields.boolean– true/false.date– ISO format.geoCoordinates– latitude/longitude pairs.uuid– unique identifier.
Built-in Functions
nearText– semantic text search.nearVector– direct embedding vector search.nearImage– search by image embeddings.hybrid– BM25 + vector combined.where filter– structured filtering (Equal,GreaterThan, etc.).groupBy– aggregate results.generative– run LLMs like OpenAI on retrieved objects.
Modules
text2vec-openai– OpenAI embeddings.text2vec-cohere– Cohere embeddings.img2vec-neural– image embeddings.qna-transformers– QA pipelines.generative-openai– Retrieval-Augmented Generation.
Example Use Cases
- Semantic Product Search – “running shoes under $100” → hybrid search with filters.
- RAG Pipelines – retrieve top-k document chunks for LLMs.
- Recommendations – similarity search on movies, products, or users.
- Knowledge Graphs – link entities with cross-references.
- Support Systems – retrieve similar tickets for faster resolution.
CRUD Examples
Create Class:
POST /v1/schema/classes
{
"class": "Article",
"vectorizer": "text2vec-openai",
"properties": [
{ "name": "title", "dataType": ["text"] },
{ "name": "url", "dataType": ["string"] },
{ "name": "published", "dataType": ["date"] }
]
}Insert Object:
POST /v1/objects
{
"class": "Article",
"properties": {
"title": "AI in Healthcare",
"url": "https://example.com/ai-healthcare",
"published": "2025-01-10T10:00:00Z"
}
}Update Object:
PATCH /v1/objects/{id}
{
"properties": {
"title": "AI in Healthcare - Updated"
}
}Retrieve Object:
{
Get {
Article(where: {
path: ["title"],
operator: Equal,
valueString: "AI in Healthcare"
}) {
title
url
}
}
}Delete Object:
DELETE /v1/objects/{id}Common Mistakes to Avoid
- Ignoring Schema – schema-first is mandatory, unlike schemaless DBs.
- Over-indexing – HNSW tuning without benchmarks can degrade performance.
- Not Using Hybrid Search – keyword + vector often gives best results.
- Forgetting Multi-tenancy – important for SaaS and isolation.
- Storing Too Large Vectors – embeddings must be consistent in dimension.
Final Thoughts
Weaviate is not just a database, it’s an AI-native vector search platform. It powers semantic product search, RAG systems, and real-time recommendations at scale.
To use Weaviate effectively:
- Design schema upfront.
- Use hybrid search for best retrieval.
- Configure replication/sharding for scale.
- Leverage modules for embeddings & RAG.
If you’re building AI-powered applications, Weaviate is the database to bet on.
Need help with systems like this?
For consulting, architecture reviews, and backend delivery work, I operate through SuberaHQ, focused on deliberate software engineering for teams building production systems.